
« Qui pense que les Data Scientist sont heureux en entreprise ? » Quand je pose cette question, j’obtiens en général un silence de cathédrale qui me confirme le malaise ou le mal-être d’un Métier qui devait, porté par la vague du Big Data et de l’Intelligence Artificielle, s’imposer comme la filière préférée de l’ère Digitale.
Force est de constater que nous sommes encore loin de la promesse initiale d’un Métier qui devait révolutionner le business et rendre les entreprises « Data driven ». Néanmoins je ne crois pas non plus à la fatalité qui conduirait à la disparition de cette profession dont certains commencent déjà à prédire le remplacement par des outils (j’en veux pour preuve l’explosion de l’offre de solutions qui font miroiter que n’importe qui pourra faire de la Data Science demain).
Pour aider tout Data Scientist actuel ou futur, voici quelques clés pour réussir sa mission. Je ne parlerai pas de machine learning, de feature, de label, de mode supervisé etc… mais plutôt d’éléments de « bon sens » pour éviter ce sentiment de frustration que je relève régulièrement dans cette profession. Ces clés de réussite sont :
- Comprendre l’Entreprise
- Manier l’art de la sémantique en milieu hostile
- Ne pas s’enfermer dans une tour d’ivoire
- Penser utile
- Trouver les gisements de données
Comprendre l’Entreprise
Quel Data Scientist peut prétendre trouver un modèle à partir des données d’une entreprise dont il connait peu l’activité et l’organisation ? Peut-on imaginer poser le bon diagnostic et le bon traitement, sur une personne, à partir d’une analyse de sang, sans rien connaitre au fonctionnement du corps humain ?
Avant de se lancer dans des activités analytiques sur les données pour découvrir les signaux faibles, ma première recommandation est de mettre de côté son arsenal de modèles statistiques et de Machine Learning, de se draper de son manteau d’humilité et de partir à la découverte de l’entreprise.
Comment s’y prendre ? Je vais me limiter à donner quelques astuces. Je développerai ce point dans un billet ultérieur.
Premier conseil, lire le dernier rapport annuel de l’entreprise. On y comprend pas toujours grand-chose s’il est trop comptable ou financier mais, pour les entreprises importantes, il donne aussi des éléments intéressants sur la stratégie et même parfois sur l’histoire de la société.
Ensuite, interviewer différents responsables des Métiers (Directeur Financier, du Marketing, service Clientèle mais aussi responsable conformité, CDO etc…). Privilégier les personnes qui ont une vue globale et transversale de l’entreprise. Ces rencontres auront aussi l’avantage de vous faire connaître et de vous « démystifier ».
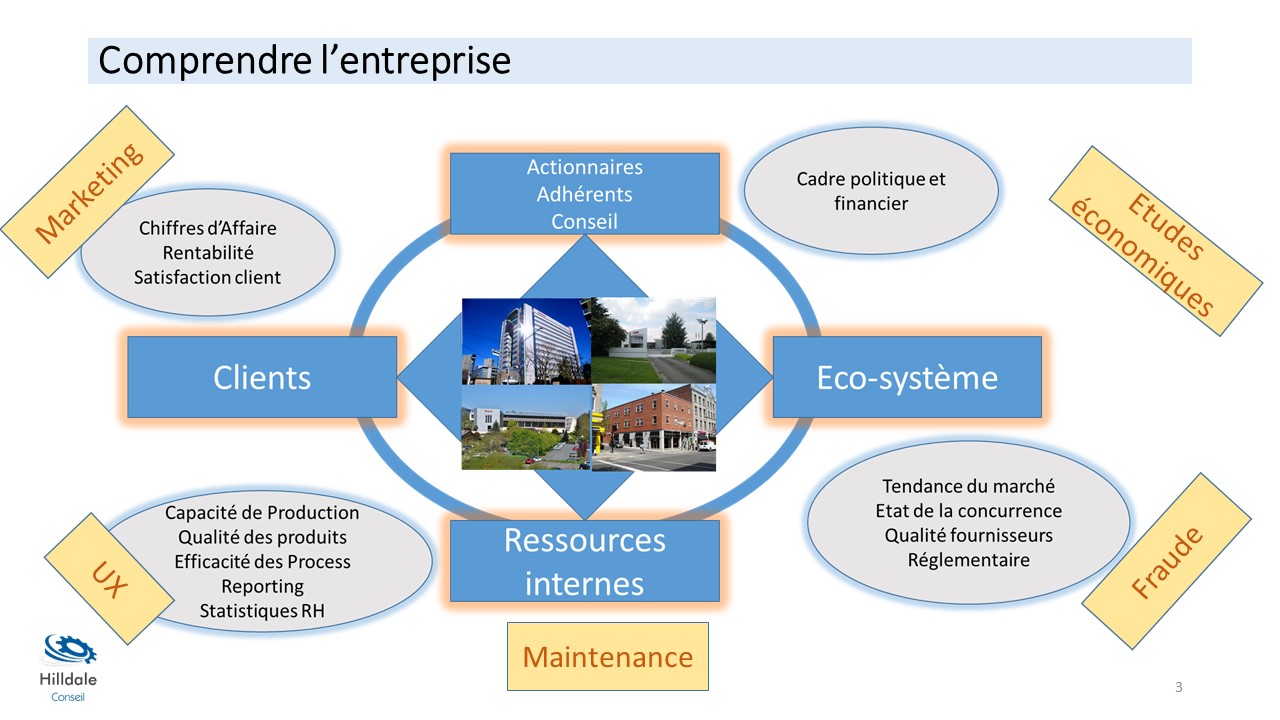
Enfin, choisir un modèle de type Balance Score Card pour prendre vos notes. Vous aurez ainsi une première macro-cartographie des blocs de données et des usages possibles de la Data Science (Voir exemple ci-dessous).
Ne jamais oublier que c’est au Data scientist de comprendre l’entreprise (et pas l’inverse) !
Manier l’art de la sémantique en milieu hostile
J’ai déjà eu l’occasion de publier deux articles sur l’importance de la sémantique et du langage commun (c’est ici et là) pour construire des modèles de qualité.
Pour se convaincre de l’importance d’un langage commun, il suffit de demander à la cantonade : quelle est la règle pour calculer le nombre de clients de l’entreprise ? Il existe autant de réponses que de points de vues : faut-il compter les prospects ? les clients sans produits ? les disparus de l’année ? deux agences avec le même client est-ce un ou deux clients ? etc… Réaliser ce test éclaire sur une réalité de l’entreprise : chaque collaborateur évolue dans le paradigme de son activité. Chacun son point de vue, chacun sa vérité.
Le Data Scientist ne peut pas s’arrêter à l’aspect mathématique ou statistique de sa discipline mais il doit bien se préoccuper du sens des mots. Ce que j’appelle l’art de la sémantique.
Pourquoi alors parler de milieu hostile en entreprise ? Trois raisons au moins : 1/le manque de pédagogie et de temps des acteurs car tout le monde n’a pas le don, l’envie ou le temps de bien expliquer ce qu’il fait – 2/le manque de transparence car tout le monde ne souhaite pas dévoiler ses « secrets » – 3/la construction paradoxale de l’entreprise où silotage des structures, injonctions contradictoires et objectifs divergents voire opposés conduisent à une vision parcellaire et déformée des concepts.
Si la fonction de Gouvernance des Données est installée dans l’entreprise, la question de la sémantique et des règles de gestion y est normalement adressée. Mais nous savons tous que ce type de structure est encore très émergent, aussi l’astuce que j’indique ici est d’utiliser les standards des marchés comme les normes (par exemple format des échanges interbancaires ou la norme Galia dans l’automobile) car ce sont des référentiels utiles pour poser les concepts de base. Ils sont suffisamment légitimes pour que les acteurs du domaine acceptent de s’aligner dessus.
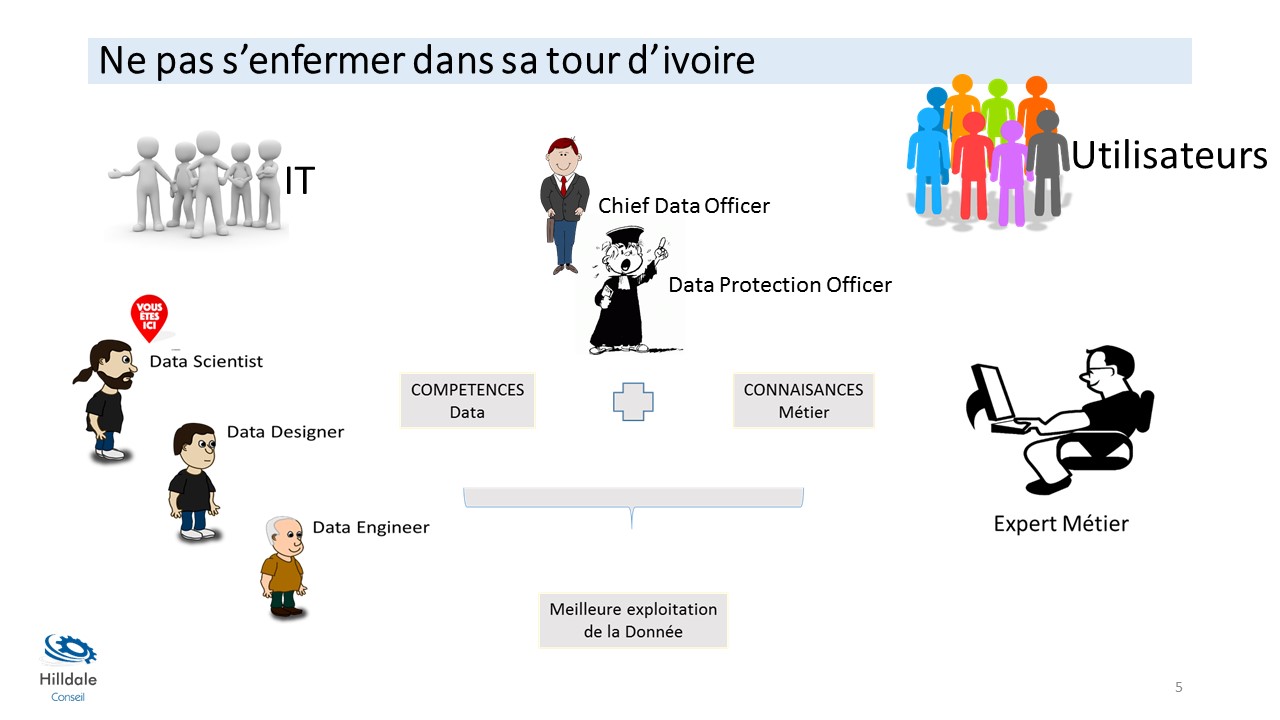
Ne pas s’enfermer dans une tour d’ivoire
Beaucoup d’entreprises ont cédé à l’idée – intellectuellement séduisante – de mettre en place des DataLab, d’y concentrer les compétences en Data Science afin que ces DataLab proposent en mode « fournisseur » interne leurs services aux différents Métiers. Cela a permis aux entreprises de monter en compétence sur la compréhension des enjeux de la Data. Les Data Scientists ont passé beaucoup de leur temps à évangéliser les foules. Mais après quelques années de ce fonctionnement, le bilan des DataLab est décevant : environ 2/3 des projets Data sont abandonnés. La succession de POC a souvent été une succession d’échecs notamment au moment de passer à l’échelle et de déployer. Cette organisation a aussi contribué à la marginalisation du Data Scientist, son découragement puis son attrition pour souvent se terminer par un départ vers d’autres cieux.
Le conseil que je donne ici est que chaque Data Scientist inscrive son action dans un processus de travail collaboratif en équipe où il met au service ses compétences. L’heure n’est plus à s’enfermer dans une tour d’ivoire car le train de la transformation digitale des entreprises ne s’y arrêtera pas . L’heure est au travail en équipe avec tous les acteurs de l’IT, tous les Métiers de la Data, les experts Métiers, les utilisateurs… Bref toutes les compétences sont à mettre en action pour une meilleure exploitation de la donnée.
Penser utile
L’entreprise n’est pas un laboratoire ! C’est une réalité qui peut décevoir les jeunes recrues fraîchement sorties de leurs écoles ou de leurs universités. Bien sûr il existe des activités de R&D, d’Innovation, d’Etudes de marché… mais ne jamais oublier qu’une entreprise a un objet social et des contraintes économiques.
La Data Science doit être une activité qui apporte de la valeur à l’entreprise dans la durée. Ce ne peut être – on l’a d’ailleurs vu plus haut – un domaine réservé dont les activités ne sont comprises que par quelques privilégiés et qui finira par souffrir du syndrome du « à quoi ça sert tout ça ? ».
5 préoccupations doivent continuellement habiter l’esprit du Data Scientist :
- La Faisabilité. « Est-ce que le modèle que j’imagine est atteignable ? » Un exemple ? S’interroger sur la fraîcheur des données disponibles permet d’éviter de construire un modèle prévu pour un usage en temps réel sur des données rafraîchies tous les…. 6 mois.
- Le Réglementaire. « Est-ce que le modèle que j’imagine est conforme ? » Indispensable d’intégrer RGPD dès lors que les données personnelles sont utilisées. Une formation à RGPD doit d’ailleurs faire partie du bagage de tout Data Scientist. Au delà de RGPD, il existe de nombreuses professions très réglementées comme la Banque, l’Assurance etc… et il ne sera pas toujours possible d’utiliser toutes les données sans passer par des cryptages, regroupement…
- L’Economique. « Est-ce que le modèle que j’imagine apporte de la valeur à l’entreprise ? » Idéalement la réponse est dans un business plan sur lequel s’adosse votre projet avec un retour sur investissement à la clé (roi). Pour les projets réglementaires, il peut être utile de penser à mesurer le risque à ne pas faire. En tout cas, les indicateurs qui mesurent l’apport de votre modèle doivent être prévus dès la conception de celui-ci.
- La Sécurité. « Est-ce que je ne crée pas une brèche de sécurité ? » Les techniques sous-jacentes sont récentes. Leur intégration dans l’architecture globale du SI de l’entreprise est souvent une innovation à mettre en oeuvre. Autant de changements qui peuvent affaiblir les défenses du SI dès lors que le point est oublié.
- L’Industrialisation. « Est-ce que le modèle que j’imagine est déployable à l’échelle de l’entreprise ? » Le dernier salon du Big Data de mars 2019 a souligné combien ce sujet était le point délicat du moment pour la réussite des projets Data. Il faut sortir de l’état d’esprit « Laboratoire » pour penser « Industriel ».
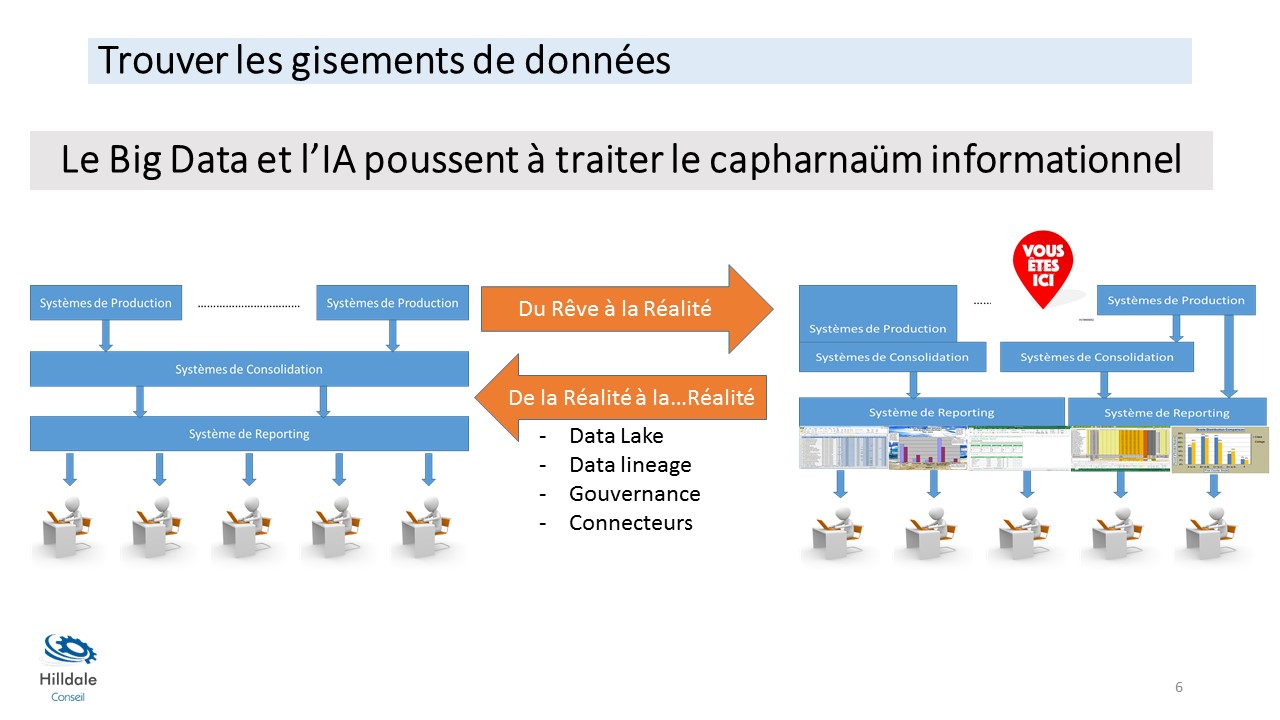
Trouver les gisements de données
Si les 4 clés précédentes sont finalement aussi très applicables à d’autres Métiers, la dernière concerne le cœur de l’activité du Data Scientist pour trouver la matière première de son activité. Arriver en entreprise, disposer rapidement de données pertinentes et de qualité pour se lancer, sans retenue, dans de la régression ou du clustering , est un rêve en général de courte durée. Il faudra se retrousser les manches et trouver les gisements de données dans un écosystème Data de l’entreprise rendu compliqué par les 3 agents de complexité que sont:
- l’évolution technologique avec des architectures au d centralisées qui se sont peu à peu réparties sous la pression de l’arrivée des serveurs, des PC, des réseaux, de l’internet et maintenant des IOT, du cloud et du digital
- l’évolution de l’architecture du SI avec la cohabitation de développements propriétaires et de progiciels mais aussi l’évolution des besoins du batch vers le temps réel qui a fait passé des fichiers séquentiels aux bases de données et maintenant aux API et aux Data Lake
- l’évolution de l’entreprise qui, au gré de l’adaptation de ses Métiers à son écosystème, de projets de fusion/acquisition avec d’autres sociétés ou de la mutualisation de moyens, finit par faire cohabiter des systèmes dans une architecture fonctionnelle et technique souvent hétéroclite où il ne sera pas aisé de déterminer la donnée pertinente.
Ces 3 agents de complexité conduisent souvent à un capharnaüm informationnel. La bonne nouvelle pour le Data Scientist est que l’émergence des enjeux du Big Data pousse les entreprises à traiter cette situation. Cependant cela reste des travaux de longue halène et la capacité de trouver les gisements de données doit être une qualité première du Data Scientist. Je conseille vivement de s’intéresser de près à l’histoire du SI de l’entreprise ce qui revient au premier point clé sur la compréhension de l’entreprise. La boucle est bouclée !
Profil idéal d’un Data Scientist en entreprise
Pour finir, quel pourrait être le profil idéal d’un Data Scientist en entreprise, en supposant acquis les bagages de sa formation à la Data Science en mathématique et, très important, en informatique. Je n’imagine pas un Data Scientist qui ne soit pas à l’aise dans la programmation et l’IT au sens large.
Pour être efficace en entreprise, un Data Scientist devra être :
- Curieux pour comprendre son environnement et trouver les données pertinentes pour ses modèles
- Empathique pour comprendre les acteurs de l’entreprise et facilité son intégration
- Collectif pour travailler en équipe
- Pédagogue pour expliquer ce qu’il fait et la valeur que ça apporte à l’entreprise
- Responsable pour s’engager à créer des modèles qui seront utiles
N’hésitez pas à réagir et à commenter cet article.
Mentions
Si vous voulez accéder à mes autres billets c’est ici
Si vous ne voulez pas manquer les prochains articles : demandez à être enregistré à mon blog
Crédit photo :
© Ecrit par Jean Méance en avril 2019

Bonjour,
Article très intéressant et qui trouvera certainement écho parmi de nombreux membres.
J’ai cependant une question :
» le bilan des DataLab est décevant : environ 2/3 des projets Data sont abandonnés. La succession de POC a souvent été une succession d’échecs notamment au moment de passer à l’échelle et de déployer. Cette organisation a aussi contribué à la marginalisation du Data Scientist, son découragement puis son attrition pour souvent se terminer par un départ vers d’autres cieux. »
Quelle est votre source pour cette information ?
Merci.
J’aimeAimé par 1 personne
Merci pour le commentaire 👍
Les 2/3 viennent d’une étude du Garrner – ils datent un peu mais vu les retours d’expériences au salon du Big Data de 2019 la tendance est là maintenue. Par ailleurs j’ai été responsable du domaine IT Pilotage renommé Data dans un grand groupe bancaire mutualiste et quand je parle de la marginalisation des ds et du turn-over c’est sur la base d’un constat vécu et aussi partagé avec des confrères.
J’aimeJ’aime